Minimax 01 : Unlocking 4M Token Long-Context Processing for AI Developers
Monday January 15, 2025 By Ethan Chueng
Introduction
The AI landscape is evolving at an unprecedented pace, and MiniMax, a leading AI company, has once again pushed the boundaries with its latest release—the MiniMax-01 series. This groundbreaking series includes two models: MiniMax-Text-01, a foundational language model, and MiniMax-VL-01, a visual-language multimodal model. These models are designed to handle ultra-long contexts and complex multimodal tasks, setting new standards for AI capabilities.
The MiniMax-01 series is not just another incremental improvement; it represents a paradigm shift in how AI models process information. With innovations like Lightning Attention and Mixture of Experts (MoE), Minimax has achieved what many thought was impossible: efficient processing of contexts up to 4 million tokens, far surpassing the capabilities of leading models like GPT-4o and Claude-3.5-Sonnet.
This blog is tailored for AI developers, offering a deep dive into the technical innovations, performance benchmarks, and practical applications of the MiniMax-01 series. Whether you're building AI agents, developing multimodal applications, or exploring long-context processing, this series is a tool you can't afford to ignore.

Minimax 01 model
Model Overview
The MiniMax-01 series is a testament to MiniMax's commitment to innovation. Here's a quick breakdown of the two models:
1. MiniMax-Text-01: A language model optimized for ultra-long context processing, capable of handling up to 4 million tokens during inference.
2. MiniMax-VL-01: A multimodal model that combines visual and language understanding, trained on 512 billion vision-language tokens.
Core Innovations:
- Lightning Attention: A novel mechanism that reduces the computational complexity of attention from quadratic to linear, enabling efficient processing of long sequences.
- Mixture of Experts (MoE): A hybrid architecture with 456 billion parameters, of which 45.9 billion are activated per token, ensuring high efficiency and scalability.
Technical Deep Dive
Lightning Attention
Traditional Transformer models struggle with long sequences due to their quadratic complexity. MiniMax's Lightning Attention solves this by dividing attention computation into intra-block and inter-block operations, maintaining linear complexity.
This innovation allows the model to process 4 million tokens efficiently, a feat unmatched by competitors.
Hybrid Architecture
The model alternates between Lightning Attention and traditional SoftMax Attention layers, combining the efficiency of the former with the precision of the latter.
Each 8-layer block includes 7 Lightning Attention layers and 1 SoftMax Attention layer, ensuring optimal performance across tasks.
Training and Optimization
Minimax employs advanced techniques like Varlen Ring Attention and LASP+ to optimize long-sequence processing and reduce computational waste.
The MoE architecture is further optimized with token grouping and EP-ETP overlapping strategies, minimizing communication overhead and maximizing resource utilization.
Performance Benchmarks
Long Context Processing
In the Ruler benchmark, MiniMax-Text-01 maintains high performance (0.910-0.963) across context lengths from 4k to 1M tokens, significantly outperforming models like Gemini-2.0-Flash.
It achieves 100% accuracy in the 4M-token Needle-In-A-Haystack retrieval task, a testament to its long-context capabilities.
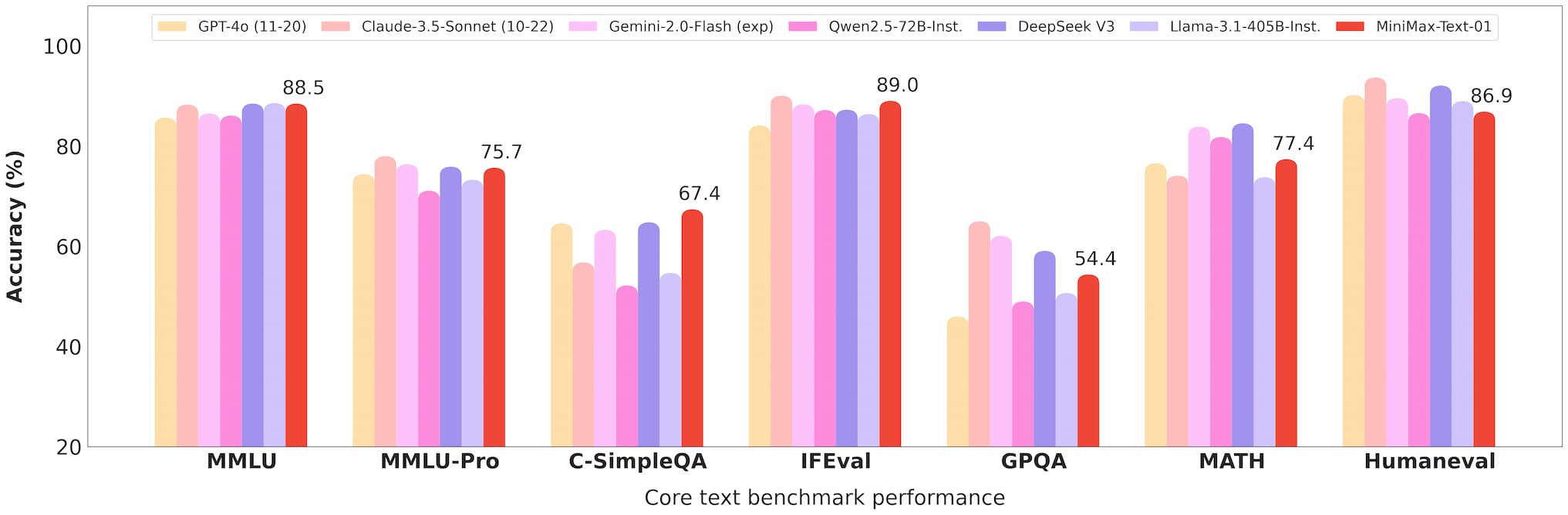
minimax 01 text benchmark
Multimodal Understanding
MiniMax-VL-01 excels in tasks like visual question answering (VQA) and image captioning, demonstrating strong performance in both academic and real-world benchmarks.
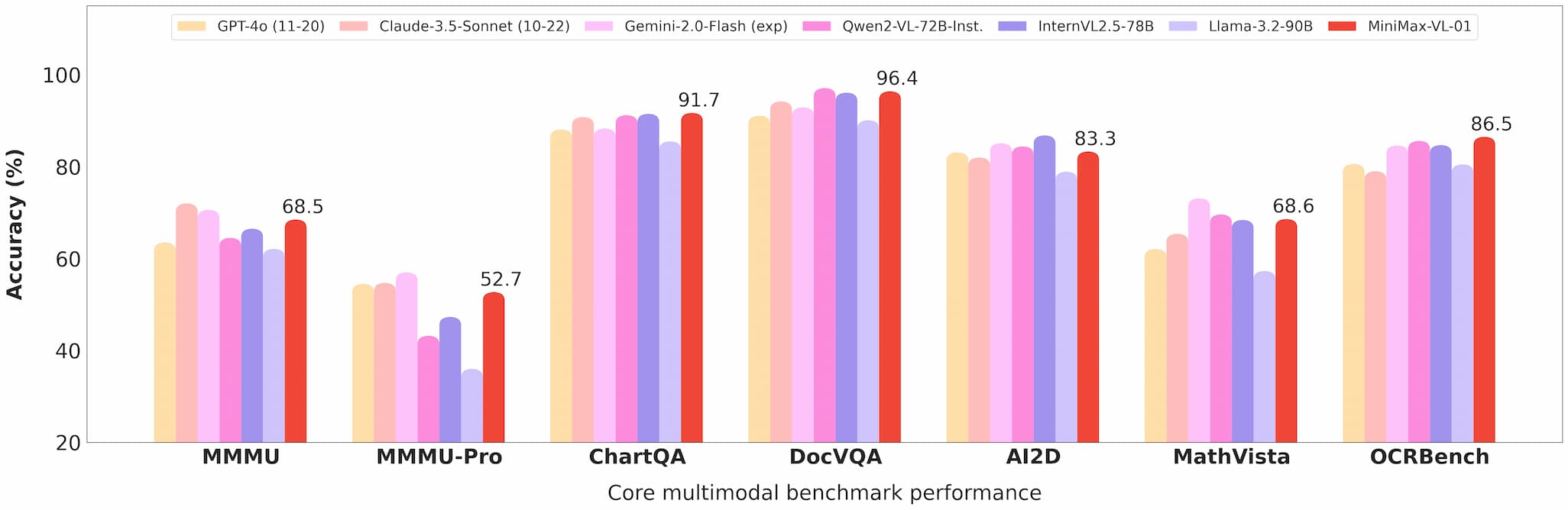
minimax 01 vision benchmark
Cost Efficiency
With API pricing at $0.2 per million input tokens and $1.6 per million output tokens, Minimax offers unparalleled value for developers.
Commercialization and Open Source
API Access
The models are available through the Minimax Open Platform, with competitive pricing and regular updates.
Developers can integrate these models into their applications with ease, thanks to comprehensive documentation and support.
Open Source
Minimax has open-sourced the complete weights of both models on GitHub and Hugging Face, encouraging community contributions and further research.
Applications
AI Agents
The ability to handle long contexts makes these models ideal for building persistent memory systems and multi-agent communication frameworks.
Multimodal Tasks
From medical imaging to autonomous driving, MiniMax-VL-01's capabilities open up new possibilities for industries requiring advanced visual-language understanding.
Cost-Effective Solutions
The low-cost API makes these models accessible to startups and small businesses, democratizing access to cutting-edge AI technology.
User Feedback and Real-World Testing
Early adopters have praised the MiniMax-01 series for its performance and versatility:
- Developers have reported seamless integration and significant improvements in tasks like document summarization and multimodal content generation.
- Researchers appreciate the open-source nature of the models, which allows for customization and experimentation.
Future Prospects
Minimax envisions a future where AI agents and multimodal systems become ubiquitous. The MiniMax-01 series is a step towards this vision, offering the tools needed to build complex, long-context AI applications.
Conclusion
The MiniMax-01 series is more than just a technological achievement; it's a catalyst for innovation in the AI community. With its unparalleled long-context processing, multimodal capabilities, and cost efficiency, this series is set to redefine what's possible in AI development.
For developers looking to stay ahead of the curve, the MiniMax-01 series is a must-explore. Visit the Minimax Open Platform or check out the GitHub repository to get started today.
Reference
For developers looking to dive deeper into the MiniMax-01 series, the following resources are invaluable:
