Minimax 01: Mở Khóa Xử Lý 4M Token Long-Context cho Nhà Phát Triển AI
Thứ Hai 15 tháng 1 năm 2025 Bởi Ethan Chueng
Giới Thiệu
Lĩnh vực AI đang phát triển với tốc độ chưa từng có, và MiniMax, một công ty AI hàng đầu, một lần nữa đã đẩy giới hạn với bản phát hành mới nhất của họ—chuỗi MiniMax-01. Chuỗi cách mạng này bao gồm hai mô hình: MiniMax-Text-01, một mô hình ngôn ngữ nền tảng, và MiniMax-VL-01, một mô hình đa chế độ thị giác-ngôn ngữ. Các mô hình này được thiết kế để xử lý ngữ cảnh siêu dài và nhiệm vụ đa chế độ phức tạp, thiết lập tiêu chuẩn mới cho khả năng AI.
Chuỗi MiniMax-01 không chỉ là một bước cải tiến nhỏ; nó đại diện cho một sự thay đổi范式 trong cách các mô hình AI xử lý thông tin. Với những đổi mới như Lightning Attention và Mixture of Experts (MoE), Minimax đã đạt được điều mà nhiều người nghĩ là không thể: xử lý hiệu quả ngữ cảnh lên đến 4 triệu token, vượt xa khả năng của các mô hình hàng đầu như GPT-4o và Claude-3.5-Sonnet.
Bài viết này được thiết kế cho các nhà phát triển AI, cung cấp một cái nhìn sâu về các đổi mới kỹ thuật, các benchmark hiệu năng và các ứng dụng thực tế của chuỗi MiniMax-01. Cho dù bạn đang xây dựng các đại lý AI, phát triển các ứng dụng đa chế độ, hoặc khám phá xử lý ngữ cảnh dài, chuỗi này là một công cụ mà bạn không thể bỏ qua.

Model Minimax 01
Tổng Quan Về Mô Hình
Chuỗi MiniMax-01 là bằng chứng về cam kết của MiniMax đối với sự đổi mới. Dưới đây là một tóm tắt nhanh của hai mô hình:
1. MiniMax-Text-01: Một mô hình ngôn ngữ được tối ưu hóa cho việc xử lý ngữ cảnh siêu dài, có khả năng xử lý lên đến 4 triệu token trong quá trình suy luận.
2. MiniMax-VL-01: Một mô hình đa chế độ kết hợp hiểu thị giác và ngôn ngữ, được đào tạo trên 512 tỷ token thị giác-ngôn ngữ.
Đổi Mới Cốt Lõi:
- Lightning Attention: Một cơ chế mới giảm độ phức tạp tính toán của sự chú ý từ bậc hai xuống bậc nhất, cho phép xử lý hiệu quả các chuỗi dài.
- Mixture of Experts (MoE): Một kiến trúc hybrid với 456 tỷ tham số, trong đó 45,9 tỷ được kích hoạt mỗi token, đảm bảo hiệu quả cao và khả năng mở rộng.
Phân Tích Kỹ Thuật
Lightning Attention
Các mô hình Transformer truyền thống gặp khó khăn với các chuỗi dài do độ phức tạp bậc hai của chúng. Lightning Attention của MiniMax giải quyết vấn đề này bằng cách chia tính toán sự chú ý thành các phép toán trong khối và giữa khối, giữ nguyên độ phức tạp bậc nhất.
Đổi mới này cho phép mô hình xử lý 4 triệu token một cách hiệu quả, một thành tựu không thể so sánh với các đối thủ cạnh tranh.
Kiến Trúc Hybrid
Mô hình này luân phiên giữa các lớp Lightning Attention và SoftMax Attention truyền thống, kết hợp hiệu quả của cái trước với độ chính xác của cái sau.
Mỗi khối 8 lớp bao gồm 7 lớp Lightning Attention và 1 lớp SoftMax Attention, đảm bảo hiệu năng tối ưu trong các nhiệm vụ.
Đào Tạo và Tối Ưu
Minimax sử dụng các kỹ thuật tiên tiến như Varlen Ring Attention và LASP+ để tối ưu hóa việc xử lý chuỗi dài và giảm thiểu lãng phí tính toán.
Kiến trúc MoE được tối ưu hóa thêm với các chiến lược nhóm token và EP-ETP overlapping, giảm thiểu chi phí giao tiếp và tối đa hóa việc sử dụng tài nguyên.
Benchmark Hiệu Năng
Xử Lý Ngữ Cảnh Dài
Trong benchmark Ruler, MiniMax-Text-01 duy trì hiệu năng cao (0,910-0,963) trên các độ dài ngữ cảnh từ 4k đến 1M token, vượt trội so với các mô hình như Gemini-2.0-Flash.
Nó đạt tỷ lệ chính xác 100% trong nhiệm vụ truy xuất Needle-In-A-Haystack với 4M token, chứng tỏ khả năng xử lý ngữ cảnh dài của nó.
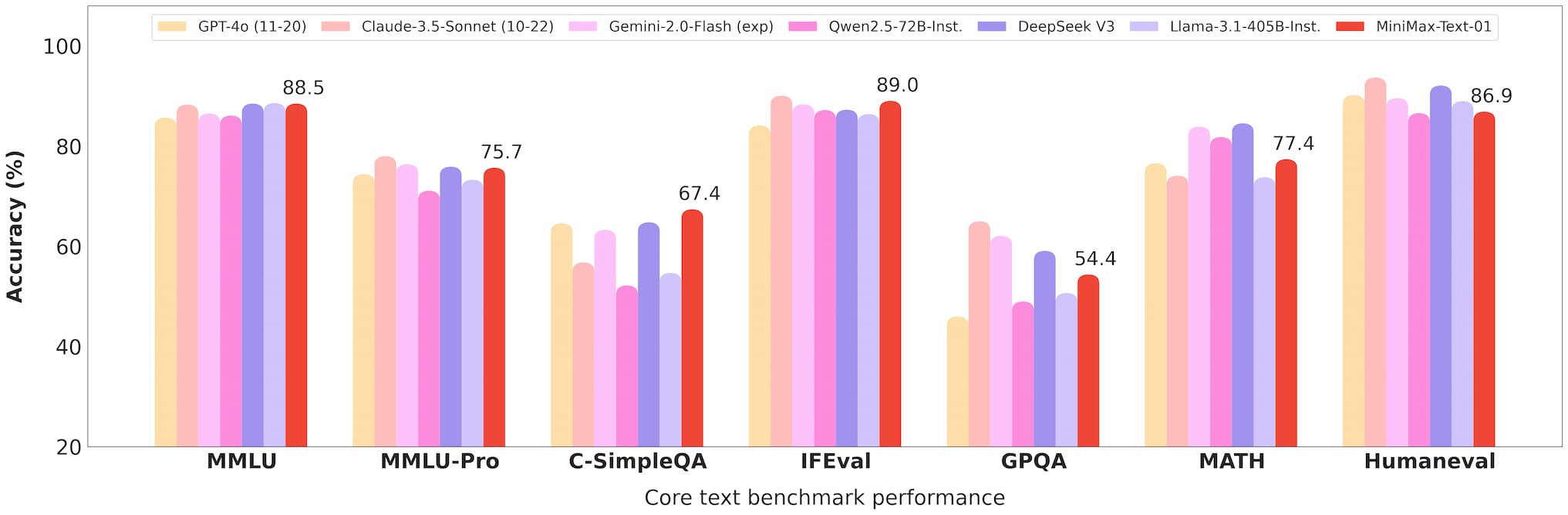
benchmark minimax 01 text
Hiểu Biết Đa Chế Độ
MiniMax-VL-01 xuất sắc trong các nhiệm vụ như trả lời câu hỏi hình ảnh (VQA) và chú thích hình ảnh, chứng tỏ hiệu năng mạnh mẽ trong các benchmark học thuật và thực tế.
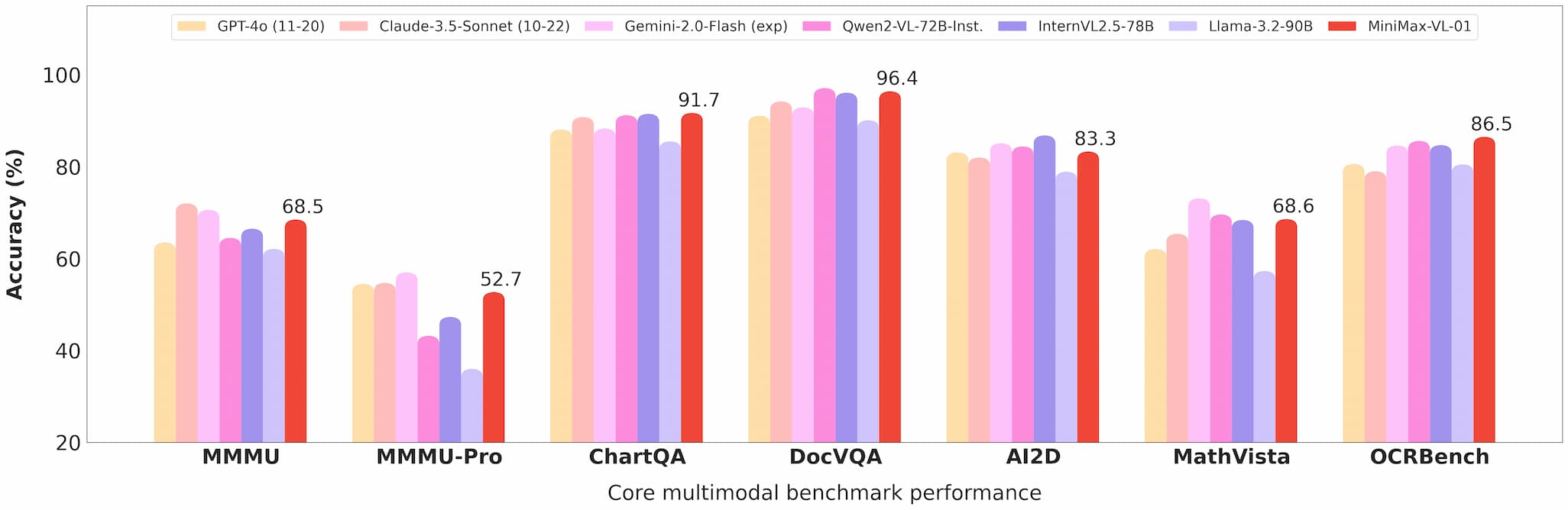
benchmark minimax 01 vision
Hiệu Quả Chi Phí
Với giá API $0,2 cho mỗi triệu token đầu vào và $1,6 cho mỗi triệu token đầu ra, Minimax cung cấp giá trị không thể so sánh cho các nhà phát triển.
Thương Mại Hóa và Mở Nguồn
Truy Cập API
Các mô hình có sẵn qua Nền Tảng Mở Minimax, với giá cả cạnh tranh và cập nhật định kỳ.
Các nhà phát triển có thể dễ dàng tích hợp các mô hình này vào ứng dụng của họ, nhờ tài liệu và hỗ trợ toàn diện.
Mở Nguồn
Minimax đã công khai toàn bộ trọng số của cả hai mô hình trên GitHub và Hugging Face, khuyến khích đóng góp của cộng đồng và nghiên cứu sâu hơn.
Ứng Dụng
Đại Lý AI
Khả năng xử lý ngữ cảnh dài làm cho các mô hình này lý tưởng để xây dựng hệ thống bộ nhớ dai và khung giao tiếp đa đại lý.
Nhiệm Vụ Đa Chế Độ
Từ hình ảnh y tế đến lái xe tự động, khả năng của MiniMax-VL-01 mở ra những khả năng mới cho các ngành yêu cầu hiểu biết thị giác-ngôn ngữ tiên tiến.
Giải Pháp Tiết Kiệm Chi Phí
API chi phí thấp làm cho các mô hình này có thể tiếp cận được với các startup và doanh nghiệp nhỏ, dân chủ hóa việc tiếp cận công nghệ AI tiên tiến.
Phản Hồi Người Dùng và Kiểm Tra Thực Tế
Người dùng đầu tiên đã ca ngợi chuỗi MiniMax-01 vì hiệu năng và đa dụng của nó:
- Các nhà phát triển đã báo cáo tích hợp trơn tru và cải thiện đáng kể trong các nhiệm vụ như tóm tắt tài liệu và tạo nội dung đa chế độ.
- Các nhà nghiên cứu đánh giá cao bản chất nguồn mở của các mô hình, cho phép tùy chỉnh và thí nghiệm.
Tương Lai
Minimax hình dung một tương lai mà các đại lý AI và hệ thống đa chế độ trở nên phổ biến. Chuỗi MiniMax-01 là một bước tiến tới tầm nhìn này, cung cấp các công cụ cần thiết để xây dựng các ứng dụng AI ngữ cảnh dài phức tạp.
Kết Luận
Chuỗi MiniMax-01 không chỉ là một thành tựu công nghệ; nó là chất xúc tác cho sự đổi mới trong cộng đồng AI. Với khả năng xử lý ngữ cảnh dài không thể so sánh, khả năng đa chế độ và hiệu quả chi phí, chuỗi này sẽ định nghĩa lại những gì có thể trong phát triển AI.
Đối với các nhà phát triển muốn dẫn đầu xu hướng, chuỗi MiniMax-01 là bắt buộc để khám phá. Hãy truy cập Nền Tảng Mở Minimax hoặc kiểm tra kho lưu trữ GitHub để bắt đầu ngay hôm nay.
Tham Khảo
Đối với các nhà phát triển muốn tìm hiểu sâu hơn về chuỗi MiniMax-01, các tài nguyên sau đây là vô giá:
