Minimax 01: Odblokowanie przetwarzania długiego kontekstu 4M tokenów dla programistów AI
Poniedziałek, 15 stycznia 2025 Autor: Ethan Chueng
Wprowadzenie
Krajobraz AI ewoluuje w niespotykanym tempie, a MiniMax, wiodąca firma AI, ponownie przesunęła granice dzięki swojemu najnowszemu wydaniu — serii MiniMax-01. Ta przełomowa seria obejmuje dwa modele: MiniMax-Text-01, podstawowy model językowy, oraz MiniMax-VL-01, multimodalny model wizualno-językowy. Modele te są zaprojektowane do obsługi ultra-długich kontekstów i złożonych zadań multimodalnych, wyznaczając nowe standardy możliwości AI.
Seria MiniMax-01 to nie tylko kolejna przyrostowa poprawka; reprezentuje zmianę paradygmatu w sposobie przetwarzania informacji przez modele AI. Dzięki innowacjom takim jak Lightning Attention i Mixture of Experts (MoE), Minimax osiągnęło to, co wielu uważało za niemożliwe: wydajne przetwarzanie kontekstów do 4 milionów tokenów, znacznie przekraczając możliwości wiodących modeli, takich jak GPT-4o i Claude-3.5-Sonnet.
Ten blog jest skierowany do programistów AI, oferując dogłębne spojrzenie na innowacje techniczne, benchmarki wydajności i praktyczne zastosowania serii MiniMax-01. Niezależnie od tego, czy budujesz agentów AI, tworzysz aplikacje multimodalne, czy eksplorujesz przetwarzanie długiego kontekstu, ta seria to narzędzie, którego nie możesz zignorować.

Model Minimax 01
Przegląd modelu
Seria MiniMax-01 jest świadectwem zaangażowania Minimax w innowacje. Oto krótki przegląd dwóch modeli:
1. MiniMax-Text-01: Model językowy zoptymalizowany do przetwarzania ultra-długiego kontekstu, zdolny do obsługi do 4 milionów tokenów podczas wnioskowania.
2. MiniMax-VL-01: Model multimodalny łączący zrozumienie wizualne i językowe, szkolony na 512 miliardach tokenów wizualno-językowych.
Kluczowe innowacje:
- Lightning Attention: Nowatorski mechanizm, który redukuje złożoność obliczeniową uwagi z kwadratowej do liniowej, umożliwiając wydajne przetwarzanie długich sekwencji.
- Mixture of Experts (MoE): Hybrydowa architektura z 456 miliardami parametrów, z których 45,9 miliarda jest aktywowanych na token, zapewniająca wysoką wydajność i skalowalność.
Techniczny deep dive
Lightning Attention
Tradycyjne modele Transformer mają problemy z długimi sekwencjami ze względu na ich kwadratową złożoność. Lightning Attention Minimax rozwiązuje ten problem, dzieląc obliczenia uwagi na operacje wewnątrzblokowe i międzyblokowe, zachowując liniową złożoność.
Ta innowacja pozwala modelowi na wydajne przetwarzanie 4 milionów tokenów, co jest osiągnięciem nieosiągalnym dla konkurencji.
Architektura hybrydowa
Model przełącza się między warstwami Lightning Attention a tradycyjnymi warstwami SoftMax Attention, łącząc wydajność pierwszej z precyzją drugiej.
Każdy 8-warstwowy blok zawiera 7 warstw Lightning Attention i 1 warstwę SoftMax Attention, zapewniając optymalną wydajność w różnych zadaniach.
Szkolenie i optymalizacja
Minimax wykorzystuje zaawansowane techniki, takie jak Varlen Ring Attention i LASP+, aby zoptymalizować przetwarzanie długich sekwencji i zmniejszyć marnotrawstwo obliczeniowe.
Architektura MoE jest dodatkowo optymalizowana dzięki strategiom grupowania tokenów i nakładania EP-ETP, minimalizując narzut komunikacyjny i maksymalizując wykorzystanie zasobów.
Benchmarki wydajności
Przetwarzanie długiego kontekstu
W benchmarku Ruler, MiniMax-Text-01 utrzymuje wysoką wydajność (0.910-0.963) w zakresie długości kontekstu od 4k do 1M tokenów, znacznie przewyższając modele takie jak Gemini-2.0-Flash.
Osiąga 100% dokładności w zadaniu wyszukiwania Needle-In-A-Haystack na 4M tokenów, co świadczy o jego możliwościach długiego kontekstu.
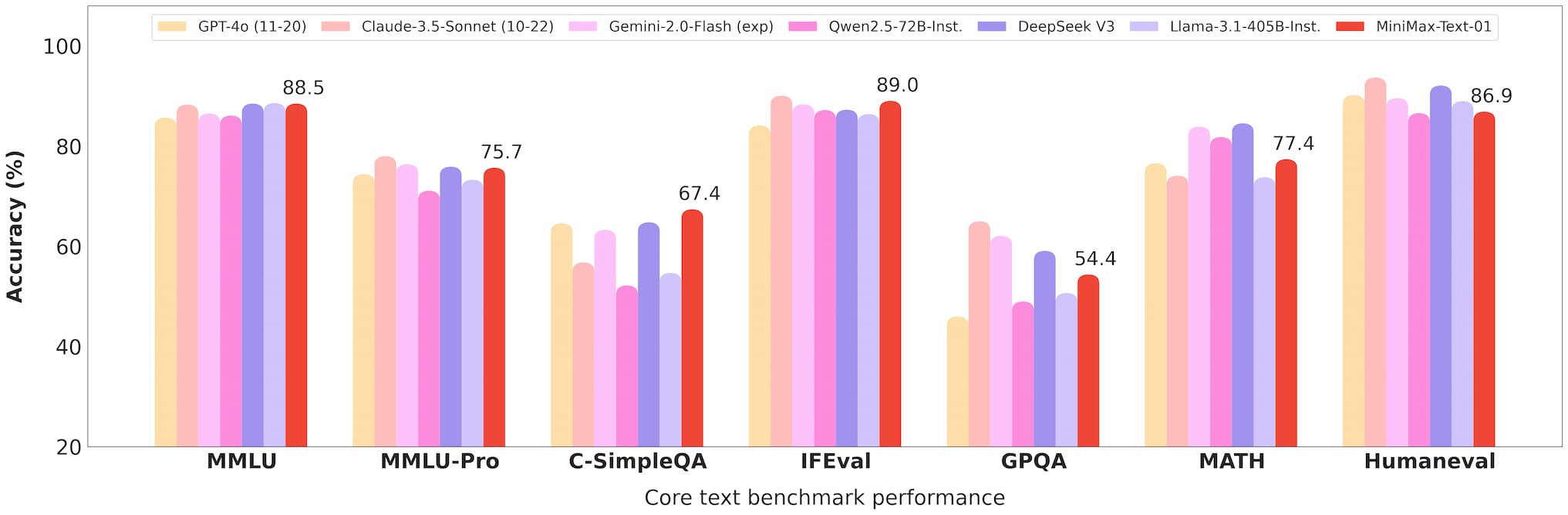
Benchmark tekstu Minimax 01
Zrozumienie multimodalne
MiniMax-VL-01 wyróżnia się w zadaniach takich jak wizualne odpowiadanie na pytania (VQA) i opisywanie obrazów, wykazując silne wyniki w benchmarkach akademickich i rzeczywistych.
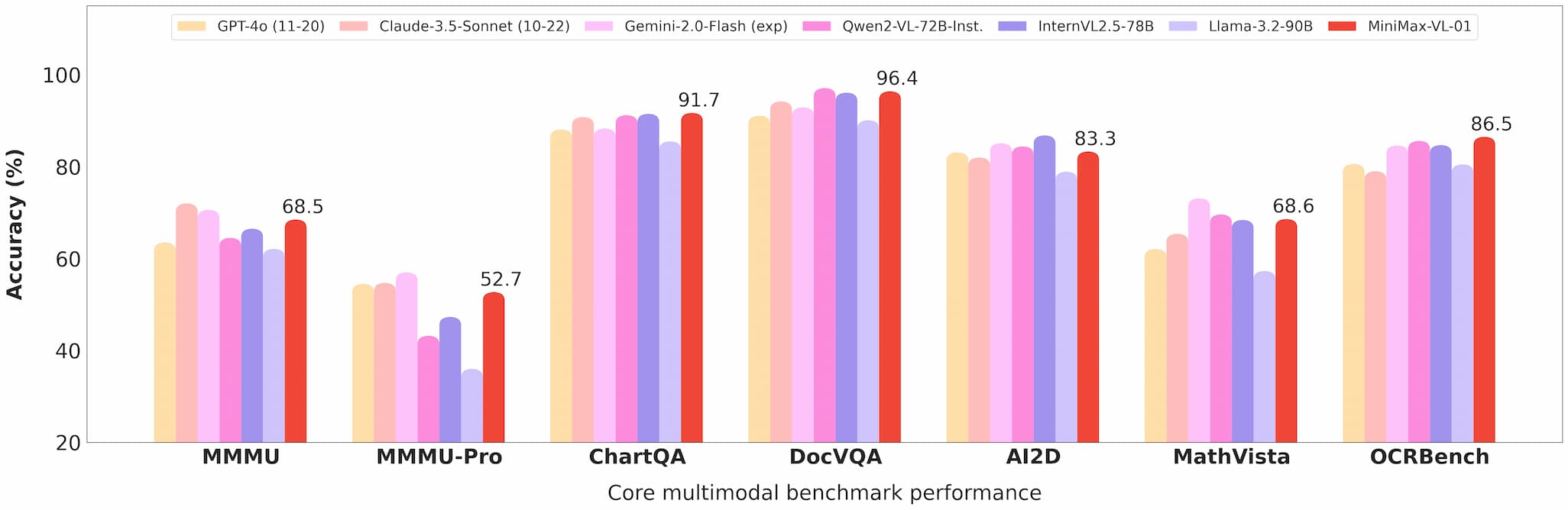
Benchmark wizji Minimax 01
Wydajność kosztowa
Przy cenach API wynoszących 0,2 USD za milion tokenów wejściowych i 1,6 USD za milion tokenów wyjściowych, Minimax oferuje niezrównaną wartość dla programistów.
Komercyjne i open source
Dostęp do API
Modele są dostępne przez platformę Minimax Open Platform, z konkurencyjnymi cenami i regularnymi aktualizacjami.
Programiści mogą łatwo zintegrować te modele w swoich aplikacjach, dzięki kompleksowej dokumentacji i wsparciu.
Open source
Minimax udostępniło pełne wagi obu modeli na GitHub i Hugging Face, zachęcając do wkładu społeczności i dalszych badań.
Zastosowania
Agenci AI
Możliwość obsługi długich kontekstów czyni te modele idealnymi do budowania systemów pamięci trwałej i frameworków komunikacji wieloagentowej.
Zadania multimodalne
Od obrazowania medycznego po jazdę autonomiczną, możliwości MiniMax-VL-01 otwierają nowe możliwości dla branż wymagających zaawansowanego zrozumienia wizualno-językowego.
Rozwiązania opłacalne
Niskokosztowe API sprawia, że te modele są dostępne dla startupów i małych firm, demokratyzując dostęp do najnowocześniejszej technologii AI.
Opinie użytkowników i testy w rzeczywistych warunkach
Pierwsi użytkownicy chwalili serię MiniMax-01 za jej wydajność i wszechstronność:
- Programiści zgłaszali płynną integrację i znaczące ulepszenia w zadaniach takich jak podsumowywanie dokumentów i generowanie treści multimodalnych.
- Badacze doceniają otwarty charakter modeli, co pozwala na dostosowanie i eksperymentowanie.
Perspektywy na przyszłość
Minimax przewiduje przyszłość, w której agenci AI i systemy multimodalne są wszechobecne. Seria MiniMax-01 to krok w tym kierunku, oferując narzędzia potrzebne do budowania złożonych aplikacji AI z długim kontekstem.
Podsumowanie
Seria MiniMax-01 to więcej niż tylko osiągnięcie technologiczne; to katalizator innowacji w społeczności AI. Dzięki bezprecedensowemu przetwarzaniu długiego kontekstu, możliwościom multimodalnym i wydajności kosztowej, ta seria redefiniuje to, co jest możliwe w rozwoju AI.
Dla programistów, którzy chcą pozostać na czele, seria MiniMax-01 to obowiązkowa eksploracja. Odwiedź platformę Minimax Open Platform lub sprawdź repozytorium GitHub, aby zacząć już dziś.
