Minimax 01: Freischaltung der 4M Token Langkontextverarbeitung für KI-Entwickler
Montag, 15. Januar 2025 Von Ethan Chueng
Einführung
Die KI-Landschaft entwickelt sich in einem beispiellosen Tempo, und MiniMax, ein führendes KI-Unternehmen, hat erneut die Grenzen mit seiner neuesten Veröffentlichung – der MiniMax-01-Serie – verschoben. Diese bahnbrechende Serie umfasst zwei Modelle: MiniMax-Text-01, ein grundlegendes Sprachmodell, und MiniMax-VL-01, ein visuell-sprachliches multimodales Modell. Diese Modelle sind für die Verarbeitung von ultra-langen Kontexten und komplexen multimodalen Aufgaben konzipiert und setzen neue Maßstäbe für KI-Fähigkeiten.
Die MiniMax-01-Serie ist nicht nur eine weitere inkrementelle Verbesserung; sie stellt einen Paradigmenwechsel dar, wie KI-Modelle Informationen verarbeiten. Mit Innovationen wie Lightning Attention und Mixture of Experts (MoE) hat Minimax erreicht, was viele für unmöglich hielten: die effiziente Verarbeitung von Kontexten mit bis zu 4 Millionen Token, was die Fähigkeiten führender Modelle wie GPT-4o und Claude-3.5-Sonnet bei weitem übertrifft.
Dieser Blog ist speziell für KI-Entwickler konzipiert und bietet einen tiefen Einblick in die technischen Innovationen, Leistungsbenchmarks und praktischen Anwendungen der MiniMax-01-Serie. Egal, ob Sie KI-Agenten entwickeln, multimodale Anwendungen erstellen oder die Langkontextverarbeitung erforschen – diese Serie ist ein Werkzeug, das Sie nicht ignorieren können.

Minimax 01 Modell
Modellübersicht
Die MiniMax-01-Serie ist ein Beweis für das Innovationsengagement von MiniMax. Hier ist eine kurze Aufschlüsselung der beiden Modelle:
1. MiniMax-Text-01: Ein Sprachmodell, das für die Verarbeitung von ultra-langen Kontexten optimiert ist und während der Inferenz bis zu 4 Millionen Token verarbeiten kann.
2. MiniMax-VL-01: Ein multimodales Modell, das visuelles und sprachliches Verständnis kombiniert und auf 512 Milliarden visuell-sprachlichen Token trainiert wurde.
Kerninnovationen:
- Lightning Attention: Ein neuartiger Mechanismus, der die rechnerische Komplexität der Aufmerksamkeit von quadratisch auf linear reduziert und so die effiziente Verarbeitung langer Sequenzen ermöglicht.
- Mixture of Experts (MoE): Eine hybride Architektur mit 456 Milliarden Parametern, von denen 45,9 Milliarden pro Token aktiviert werden, was hohe Effizienz und Skalierbarkeit gewährleistet.
Technischer Deep Dive
Lightning Attention
Traditionelle Transformer-Modelle kämpfen mit langen Sequenzen aufgrund ihrer quadratischen Komplexität. MiniMax's Lightning Attention löst dies, indem es die Aufmerksamkeitsberechnung in intra-block und inter-block Operationen unterteilt und dabei lineare Komplexität beibehält.
Diese Innovation ermöglicht es dem Modell, 4 Millionen Token effizient zu verarbeiten, eine Leistung, die von der Konkurrenz nicht erreicht wird.
Hybride Architektur
Das Modell wechselt zwischen Lightning Attention und traditionellen SoftMax Attention-Schichten und kombiniert so die Effizienz der ersteren mit der Präzision der letzteren.
Jeder 8-Schichten-Block enthält 7 Lightning Attention-Schichten und 1 SoftMax Attention-Schicht, was eine optimale Leistung über verschiedene Aufgaben hinweg gewährleistet.
Training und Optimierung
Minimax setzt fortschrittliche Techniken wie Varlen Ring Attention und LASP+ ein, um die Langsequenzverarbeitung zu optimieren und Rechenverschwendung zu reduzieren.
Die MoE-Architektur wird weiter optimiert durch Token-Gruppierung und EP-ETP-Überlappungsstrategien, was den Kommunikationsaufwand minimiert und die Ressourcennutzung maximiert.
Leistungsbenchmarks
Langkontextverarbeitung
Im Ruler-Benchmark behält MiniMax-Text-01 eine hohe Leistung (0,910-0,963) über Kontextlängen von 4k bis 1M Token bei und übertrifft dabei Modelle wie Gemini-2.0-Flash deutlich.
Es erreicht 100% Genauigkeit in der 4M-Token Needle-In-A-Haystack-Retrieval-Aufgabe, ein Beweis für seine Langkontextfähigkeiten.
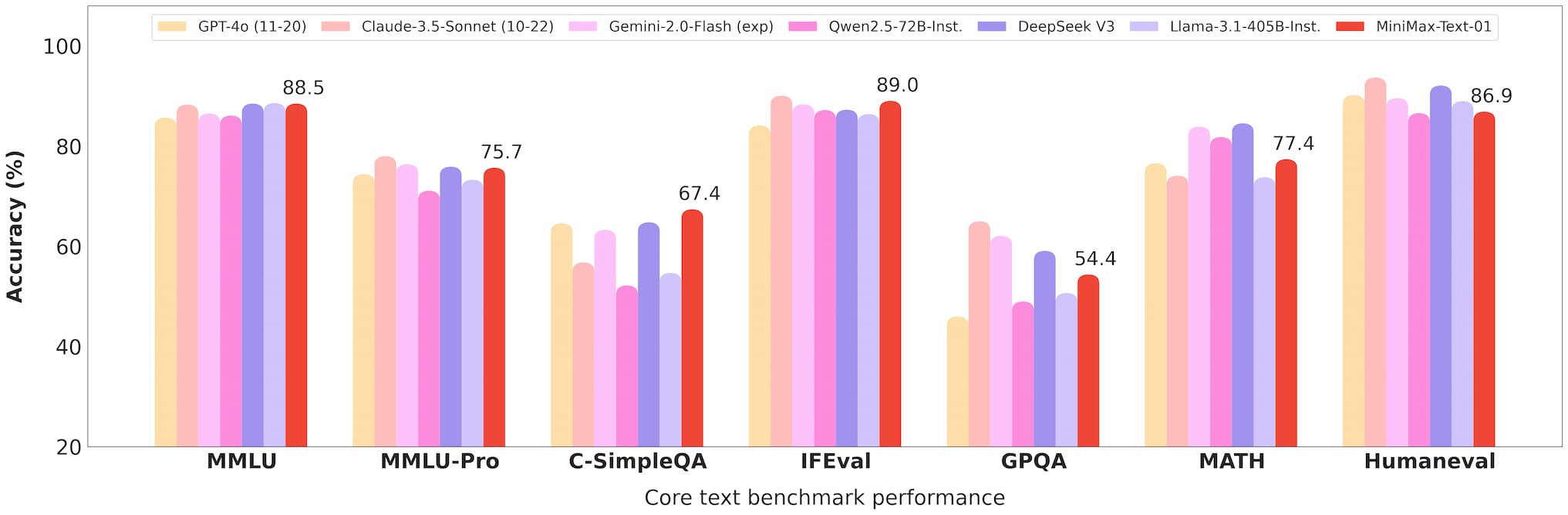
Minimax 01 Text Benchmark
Multimodales Verständnis
MiniMax-VL-01 glänzt in Aufgaben wie visueller Fragebeantwortung (VQA) und Bildbeschriftung und zeigt starke Leistungen in akademischen und realen Benchmarks.
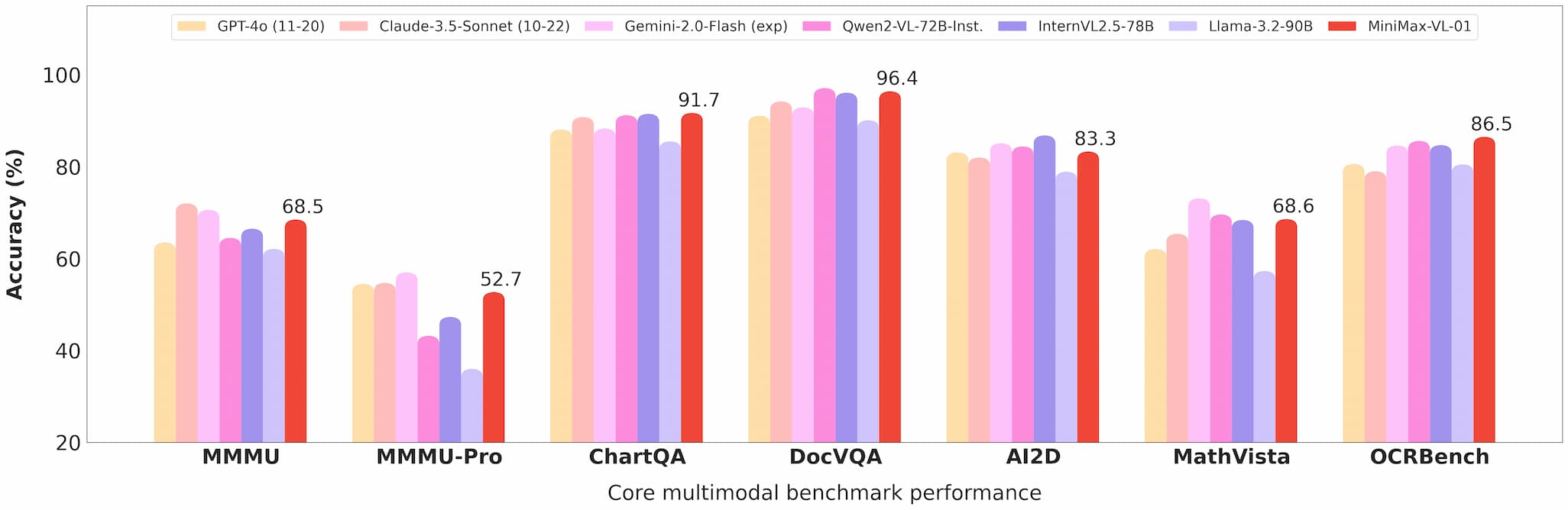
Minimax 01 Vision Benchmark
Kosteneffizienz
Mit API-Preisen von 0,2 $ pro Million Eingabe-Token und 1,6 $ pro Million Ausgabe-Token bietet Minimax unübertroffenen Wert für Entwickler.
Kommerzialisierung und Open Source
API-Zugriff
Die Modelle sind über die Minimax Open Platform verfügbar, mit wettbewerbsfähigen Preisen und regelmäßigen Updates.
Entwickler können diese Modelle dank umfassender Dokumentation und Unterstützung leicht in ihre Anwendungen integrieren.
Open Source
Minimax hat die vollständigen Gewichte beider Modelle auf GitHub und Hugging Face open source gestellt, was Community-Beiträge und weitere Forschung fördert.
Anwendungen
KI-Agenten
Die Fähigkeit, lange Kontexte zu verarbeiten, macht diese Modelle ideal für den Aufbau von persistenten Speichersystemen und Multi-Agenten-Kommunikationsframeworks.
Multimodale Aufgaben
Von der medizinischen Bildgebung bis zum autonomen Fahren eröffnen die Fähigkeiten von MiniMax-VL-01 neue Möglichkeiten für Branchen, die ein fortgeschrittenes visuell-sprachliches Verständnis erfordern.
Kosteneffektive Lösungen
Die kostengünstige API macht diese Modelle für Startups und kleine Unternehmen zugänglich und demokratisiert den Zugang zu modernster KI-Technologie.
Benutzerfeedback und reale Tests
Frühe Anwender haben die MiniMax-01-Serie für ihre Leistung und Vielseitigkeit gelobt:
- Entwickler berichten von nahtloser Integration und signifikanten Verbesserungen bei Aufgaben wie Dokumentenzusammenfassung und multimodaler Inhaltsgenerierung.
- Forscher schätzen die Open-Source-Natur der Modelle, die Anpassung und Experimente ermöglicht.
Zukunftsaussichten
Minimax sieht eine Zukunft vor, in der KI-Agenten und multimodale Systeme allgegenwärtig sind. Die MiniMax-01-Serie ist ein Schritt in diese Richtung und bietet die Werkzeuge, die benötigt werden, um komplexe, langkontextbasierte KI-Anwendungen zu entwickeln.
Fazit
Die MiniMax-01-Serie ist mehr als nur eine technologische Errungenschaft; sie ist ein Katalysator für Innovation in der KI-Community. Mit ihrer beispiellosen Langkontextverarbeitung, multimodalen Fähigkeiten und Kosteneffizienz ist diese Serie dabei, das, was in der KI-Entwicklung möglich ist, neu zu definieren.
Für Entwickler, die an der Spitze bleiben wollen, ist die MiniMax-01-Serie ein Muss. Besuchen Sie die Minimax Open Platform oder sehen Sie sich das GitHub-Repository an, um noch heute zu beginnen.
Referenzen
Für Entwickler, die tiefer in die MiniMax-01-Serie eintauchen möchten, sind die folgenden Ressourcen unverzichtbar:
