Minimax 01: فك تشفير معالجة السياق الطويل لـ 4M Token لمطوري الذكاء الاصطناعي
الاثنين 15 يناير 2025 بقلم إيثان تشونغ
مقدمة
يتطور مشهد الذكاء الاصطناعي بوتيرة غير مسبوقة، ودفعت MiniMax، وهي شركة رائدة في مجال الذكاء الاصطناعي، الحدود مرة أخرى مع إطلاقها الأخير — سلسلة MiniMax-01. تتضمن هذه السلسلة الرائدة نموذجين: MiniMax-Text-01، نموذج اللغة الأساسي، وMiniMax-VL-01، نموذج الوسائط المتعددة البصري-اللغوي. تم تصميم هذه النماذج للتعامل مع السياقات فائقة الطول والمهام متعددة الوسائط المعقدة، مما يضع معايير جديدة لقدرات الذكاء الاصطناعي.
سلسلة MiniMax-01 ليست مجرد تحسين تدريجي آخر؛ إنها تمثل تحولًا paradigmi في كيفية معالجة نماذج الذكاء الاصطناعي للمعلومات. مع ابتكارات مثل Lightning Attention وMixture of Experts (MoE)، حققت Minimax ما اعتقد الكثيرون أنه مستحيل: معالجة فعالة للسياقات التي تصل إلى 4 ملايين token، متفوقة بشكل كبير على إمكانيات النماذج الرائدة مثل GPT-4o وClaude-3.5-Sonnet.
تم تصميم هذه المدونة لمطوري الذكاء الاصطناعي، وتقدم نظرة عميقة على الابتكارات التقنية، ومعايير الأداء، والتطبيقات العملية لسلسلة MiniMax-01. سواء كنت تبني وكلاء ذكاء اصطناعي، أو تطوير تطبيقات متعددة الوسائط، أو استكشاف معالجة السياق الطويل، فإن هذه السلسلة هي أداة لا يمكنك تجاهلها.

نموذج Minimax 01
نظرة عامة على النموذج
سلسلة MiniMax-01 هي دليل على التزام Minimax بالابتكار. إليك تفصيل سريع للنموذجين:
1. MiniMax-Text-01: نموذج لغوي مُحسّن لمعالجة السياق فائق الطول، قادر على التعامل مع ما يصل إلى 4 ملايين token أثناء الاستدلال.
2. MiniMax-VL-01: نموذج متعدد الوسائط يجمع بين الفهم البصري واللغوي، مدرب على 512 مليار token بصري-لغوي.
الابتكارات الأساسية:
- Lightning Attention: آلية جديدة تقلل من التعقيد الحسابي للانتباه من تربيعي إلى خطي، مما يتيح معالجة فعالة للسلاسل الطويلة.
- Mixture of Experts (MoE): بنية هجينة تحتوي على 456 مليار معلمة، يتم تنشيط 45.9 مليار منها لكل token، مما يضمن كفاءة عالية وقابلية للتوسع.
الغوص التقني العميق
Lightning Attention
تعاني نماذج Transformer التقليدية من السلاسل الطويلة بسبب تعقيدها التربيعي. يحل Lightning Attention من Minimax هذه المشكلة عن طريق تقسيم حساب الانتباه إلى عمليات داخلية وخارجية، مع الحفاظ على التعقيد الخطي.
يتيح هذا الابتكار للنموذج معالجة 4 ملايين token بشكل فعال، وهو إنجاز لا مثيل له من قبل المنافسين.
الهيكل الهجين
يتناوب النموذج بين طبقات Lightning Attention وSoftMax Attention التقليدية، مما يجمع بين كفاءة الأولى ودقة الأخيرة.
تتضمن كل كتلة من 8 طبقات 7 طبقات Lightning Attention وطبقة واحدة SoftMax Attention، مما يضمن أداءً مثاليًا عبر المهام.
التدريب والتحسين
تستخدم Minimax تقنيات متقدمة مثل Varlen Ring Attention وLASP+ لتحسين معالجة السلاسل الطويلة وتقليل الهدر الحسابي.
تم تحسين بنية MoE بشكل أكبر مع استراتيجيات تجميع الـ token وEP-ETP المتداخلة، مما يقلل من النفقات العامة للاتصال ويعظم استخدام الموارد.
معايير الأداء
معالجة السياق الطويل
في معيار Ruler، يحافظ MiniMax-Text-01 على أداء عالي (0.910-0.963) عبر أطوال السياق من 4k إلى 1M token، متفوقًا بشكل كبير على نماذج مثل Gemini-2.0-Flash.
يحقق دقة بنسبة 100% في مهمة استرجاع Needle-In-A-Haystack ذات الـ 4M token، وهو دليل على قدراته في السياق الطويل.
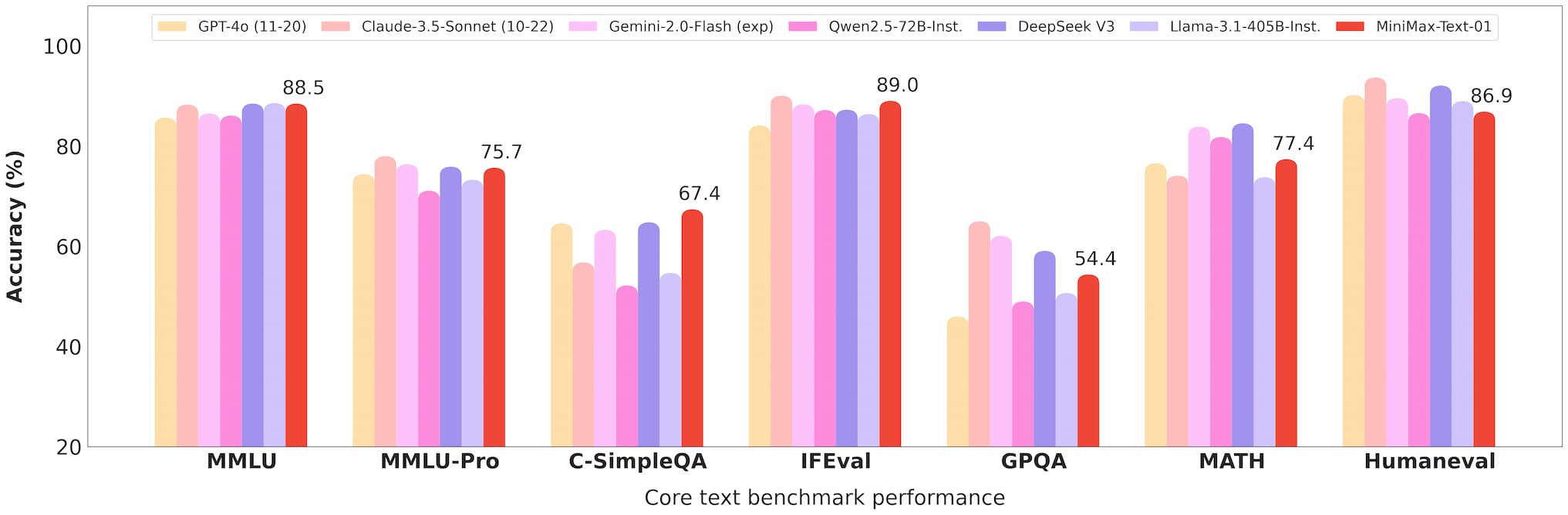
معيار نص Minimax 01
الفهم متعدد الوسائط
يتفوق MiniMax-VL-01 في مهام مثل الإجابة على الأسئلة البصرية (VQA) ووصف الصور، مما يظهر أداءً قويًا في المعايير الأكاديمية والعالمية.
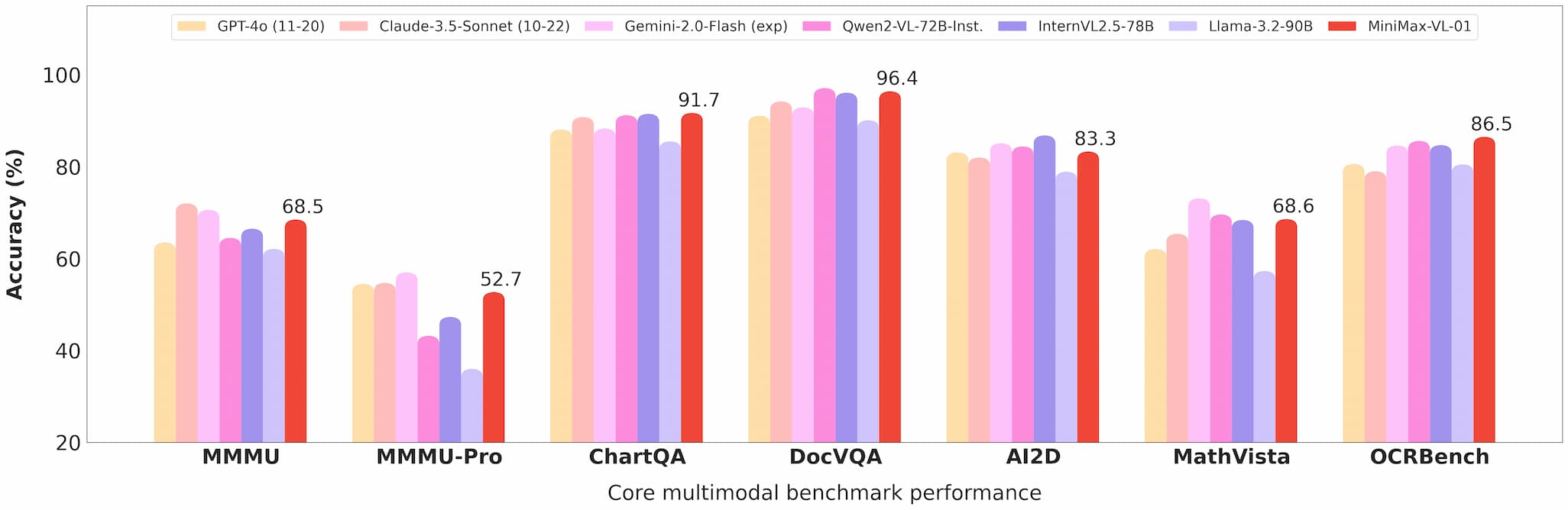
معيار رؤية Minimax 01
الكفاءة التكلفة
مع تسعير API بقيمة 0.2 دولار لكل مليون token مدخل و1.6 دولار لكل مليون token مخرج، تقدم Minimax قيمة غير مسبوقة للمطورين.
التجارية والمصادر المفتوحة
وصول API
النماذج متاحة من خلال منصة Minimax Open Platform، مع تسعير تنافسي وتحديثات منتظمة.
يمكن للمطورين دمج هذه النماذج في تطبيقاتهم بسهولة، بفضل الوثائق الشاملة والدعم.
المصادر المفتوحة
قامت Minimax بفتح المصدر الكامل لأوزان النموذجين على GitHub وHugging Face، مما يشجع على مساهمات المجتمع والمزيد من البحث.
التطبيقات
وكلاء الذكاء الاصطناعي
القدرة على التعامل مع السياقات الطويلة تجعل هذه النماذج مثالية لبناء أنظمة ذاكرة دائمة وأطر اتصال متعددة الوكلاء.
المهام متعددة الوسائط
من التصوير الطبي إلى القيادة الذاتية، تفتح إمكانيات MiniMax-VL-01 آفاقًا جديدة للصناعات التي تتطلب فهمًا متقدمًا للوسائط البصرية-اللغوية.
حلول فعالة من حيث التكلفة
يجعل API منخفض التكلفة هذه النماذج في متناول الشركات الناشئة والصغيرة، مما يديم الوصول إلى تكنولوجيا الذكاء الاصطناعي المتطورة.
تعليقات المستخدمين والاختبارات الواقعية
أشاد المستخدمون الأوائل بسلسلة MiniMax-01 لأدائها وتعدد استخداماتها:
- أبلغ المطورون عن تكامل سهل وتحسينات كبيرة في مهام مثل تلخيص المستندات وإنشاء المحتوى متعدد الوسائط.
- يقدر الباحثون طبيعة المصادر المفتوحة للنماذج، مما يسمح بالتخصيص والتجريب.
الآفاق المستقبلية
تتطلع Minimax إلى مستقبل تصبح فيه وكلاء الذكاء الاصطناعي والأنظمة متعددة الوسائط شائعة. تعد سلسلة MiniMax-01 خطوة نحو هذا الرؤية، حيث تقدم الأدوات اللازمة لبناء تطبيقات ذكاء اصطناعي معقدة وطويلة السياق.
الاستنتاج
سلسلة MiniMax-01 ليست مجرد إنجاز تكنولوجي؛ إنها محفز للابتكار في مجتمع الذكاء الاصطناعي. مع معالجة السياق الطويل غير المسبوقة، وقدراتها متعددة الوسائط، وكفاءتها التكلفة، فإن هذه السلسلة على وشك إعادة تعريف ما هو ممكن في تطوير الذكاء الاصطناعي.
للمطورين الذين يتطلعون إلى البقاء في المقدمة، تعد سلسلة MiniMax-01 أمرًا لا بد من استكشافه. قم بزيارة منصة Minimax Open Platform أو تحقق من مستودع GitHub للبدء اليوم.
المراجع
للمطورين الذين يتطلعون إلى الغوص بشكل أعمق في سلسلة MiniMax-01، فإن الموارد التالية لا تقدر بثمن:
